About the Project
In an era where images shape our collective memory, Visions reimagines the blurred boundaries between reality, fantasy, and human recollection. Combining AI-generated imagery with insights from cognitive science, this collection explores memory as inherently creative—always prone to distortion and reconstruction. Each piece emerges from a dialogue between machine-generated visuals and the human tendency to fill memory gaps with imagination. Challenging our notions of authenticity, the artworks question if AI creations can evoke emotions akin to human-made pieces. By utilizing neural networks, image analysis, and generative processes, Visions confronts our susceptibility to illusions and manipulation. This fusion of computational artistry and human reflection reveals the evolving nature of truth in a world where seeing is no longer believing but becoming, offering viewers an immersive journey into the shifting terrains of perception and memory.
In an era where images define our collective memory, “Visions” reimagines the delicate boundaries between fact, fantasy, and the shifting terrains of human recollection. This collection merges AI-generated imagery with the fragmentary nature of human memory, challenging our understanding of authenticity in an age when both brain and machine can seamlessly invent, distort, and reconstruct what we see. Rooted in research on cognitive science, the works explore the notion that memory itself is a creative act—always subject to distortion, insertion, and erasure. Each piece is a dialogue between an AI model’s “recollection” of millions of images and the human mind’s tendency to fill in gaps with imagination. In the layering of neural-network outputs, once-familiar visuals become dreamlike, raising the question: Can a painting conjured by a machine carry the same emotional power as one born of the human hand? “Visions” stands at the crossroads of reality and simulation, echoing a world that Jean Baudrillard might call “hyperreal.” Here, the absence of any original referent blurs the very idea of authenticity—what does it mean for an artwork to be “genuine,” if its origins lie in an algorithm’s generative seed? Yet beyond the newness of AI art, “Visions” beckons a return to the fundamentals of what it means to see. By harnessing object-recognition, image-analysis, and generative inpainting, the works challenge us to confront our own susceptibility to illusions. In the same way the mind can misconstrue details of a painting seen decades ago, these AI-crafted images can evoke a sense of déjà vu, even if they never existed in physical space. “Visions” grapples with AI’s capacity for manipulation. The collection underscores the technology’s double-edged sword: it can expand our creative horizons or undermine our trust in visual evidence. In moments of startling realism, the viewer is left to wonder: If an AI-generated memory feels this convincing, how easily can our own narratives be reshaped—by ourselves, by others, or by machines? In this fusion of computational artistry and human reflection, “Visions” transcends the novelty of AI. It becomes a mirror—of our desires, our doubts, our shifting notion of truth. Step into these images, and sense the blur between the authentic and the imagined, the line where human recollection meets the ever-proliferating archives of a machine’s dataset. This is a realm where the future of art, memory, and perception converge, offering a timely reminder that seeing is no longer believing, but becoming. You can find all project artworks here. https://drive.google.com/drive/folders/1Rf-wnxXfa8PX0unS62FG5Ikcq2CPeBxg?usp=sharing
AI Tools & Workflow
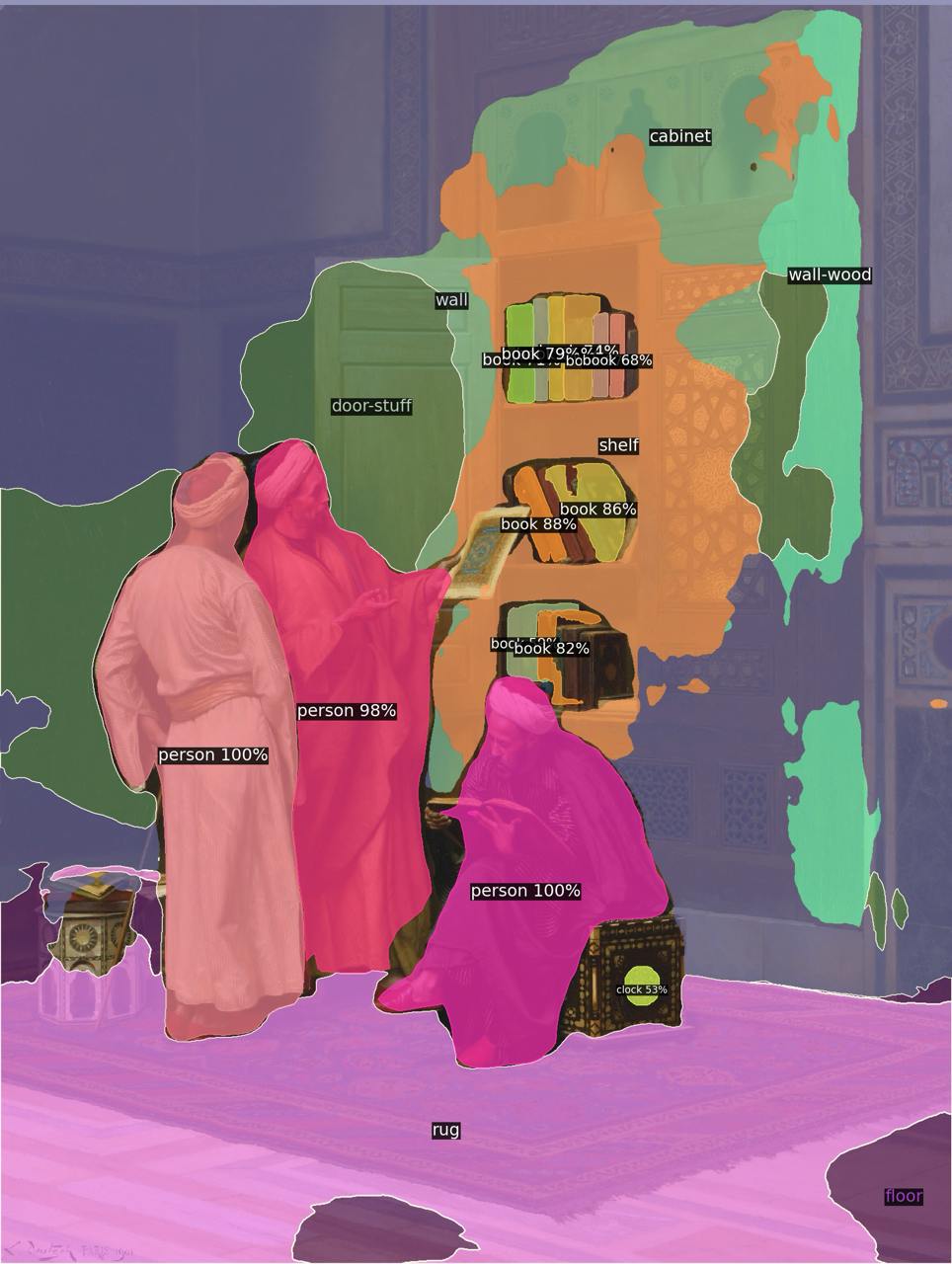
Visions utilizes a dual-pipeline technical architecture integrating advanced AI image-generation with real-time visualization. The primary Python pipeline prepares datasets, applies Flux’s diffusion models for outpainting, and leverages MiniCPM-V for vision-language image analysis. Object detection and captioning are executed via Florence-2, with segmentation masks generated using SAM. An iterative feedback loop continuously selects and inpaints objects based on relevance metrics, maintaining visual coherence and evolving compositions. Simultaneously, a TouchDesigner pipeline visualizes transformations, analytics, object relations, depth estimation (Depth Anything), and pose detection (Detectron-2) in real-time, applying dynamic shaders informed by depth data. The stack combines PyTorch, Transformers, OpenCV, and ComfyUI frameworks, with inference accelerated by NVIDIA A40 GPUs (cloud) and local development on MacBook M2 Max. This continuous, iterative AI-driven workflow results in dynamic visual compositions that evolve seamlessly through ongoing machine-human interplay.